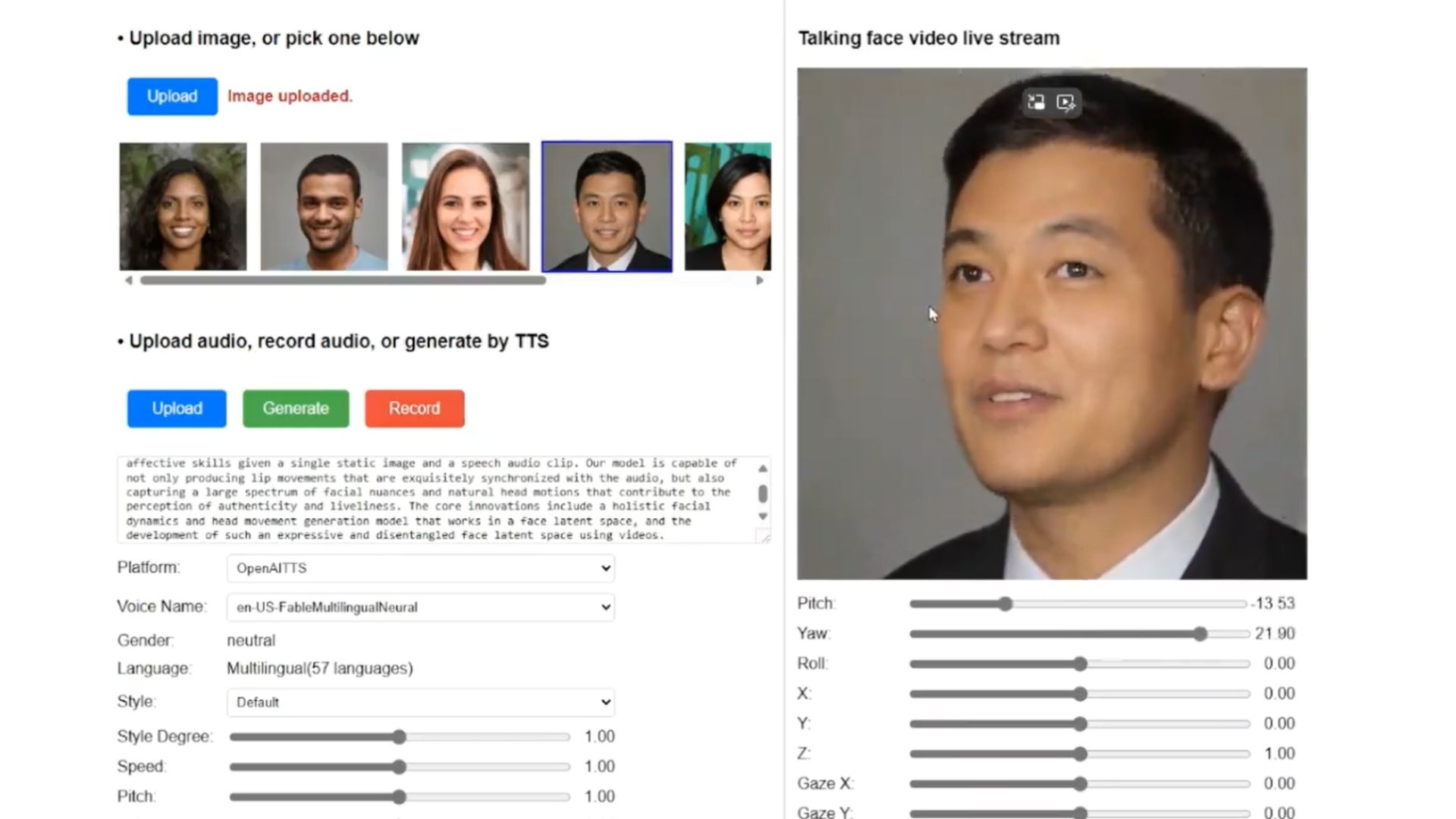
Pesquisadores da Microsoft Research Lab em Pequim, China, apresentaram o VASA-1, um novo modelo de inteligência artificial (IA) que produz vídeos realistas de rostos humanos a partir de uma única foto e um clipe de áudio. Esses vídeos curtos conferem movimentos, expressões faciais e sincronização labial extremamente convincentes, capazes de enganar um espectador desatento.
Além de animar rostos humanos, o VASA-1 pode dar vida a imagens artísticas, como personagens fictícios e obras de arte, e até gerar falas em diversos idiomas e cantos. Para a geração de fala, basta incluir um clipe de áudio com a voz desejada, que pode ser a do indivíduo da foto ou não.
Como a IA funciona?
A ferramenta oferece controle sobre expressões faciais, direção do olhar, posição da cabeça, ângulo da câmera e outros ajustes detalhados. Tudo isso pode ser manipulado em tempo real, semelhante à criação de personagens em um videogame. Os vídeos gerados têm resolução de 512×512 pixels e podem chegar a 40 quadros por segundo.
🚨 Microsoft Research just announced VASA-1.
All it needs is a picture and audio to create these talking videos!
Look at this real-time demo: pic.twitter.com/dmEIWid3XE
— Alvaro Cintas (@dr_cintas) April 18, 2024
Os pesquisadores responsáveis pela ferramenta reconhecem que sua tecnologia pode ser utilizada para criar deepfakes e potencialmente enganar pessoas. Por essa razão, eles afirmam que só comercializarão o produto quando estiverem seguros de que será usado de maneira responsável e em conformidade com as regulamentações adequadas.
A equipe acredita que a tecnologia pode melhorar a equidade educacional, o aumento da acessibilidade para pessoas com dificuldades de comunicação, a prestação de companhia ou apoio terapêutico a quem precisa, entre outros.